
Overview#
This project is a full-stack platform engineering build covering the complete delivery lifecycle on AWS — from infrastructure provisioning to production deployments, with security and observability woven in throughout.
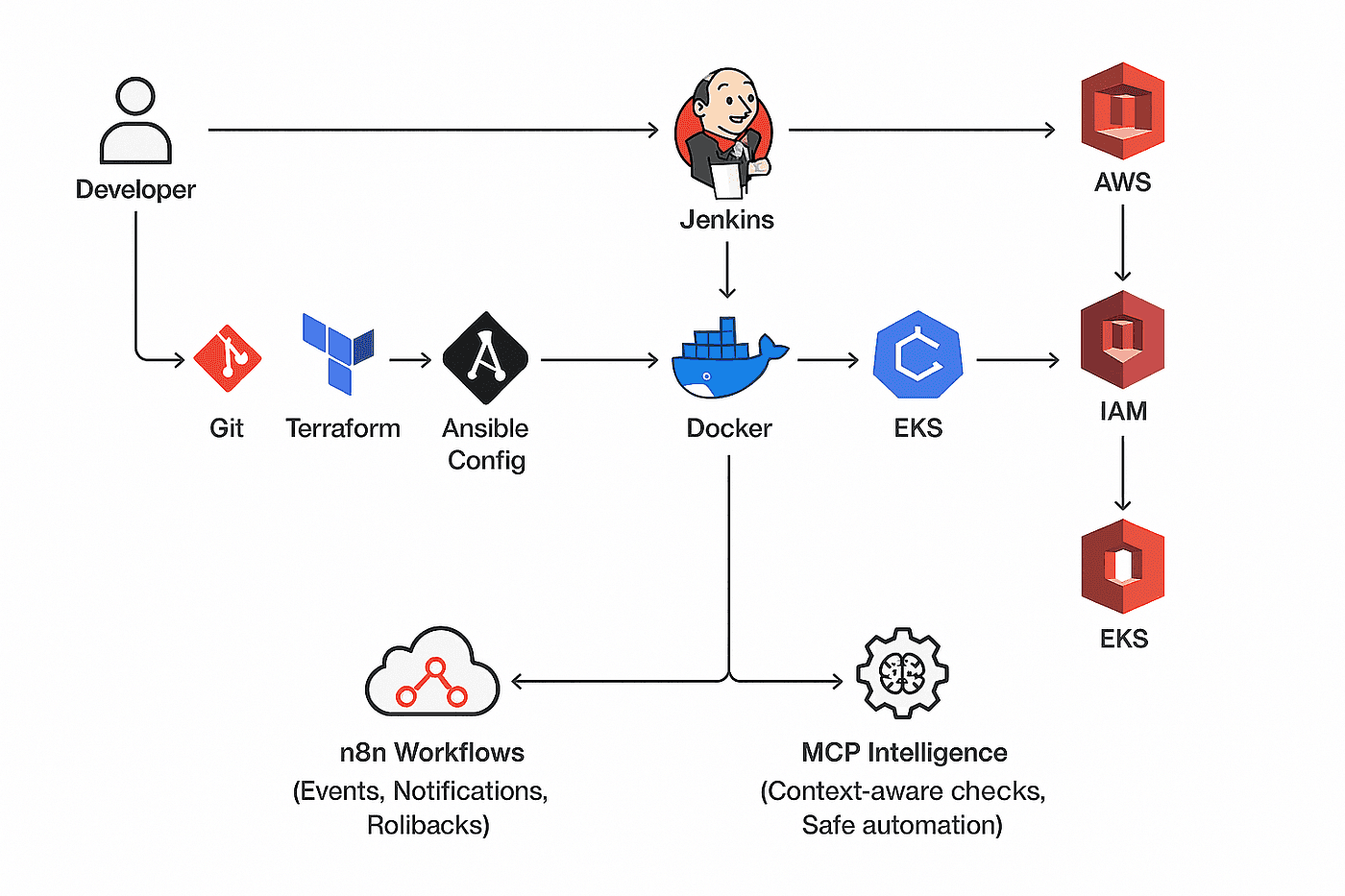
The goal was to build the kind of platform a growing engineering team could actually run in production: environment-isolated Terraform state, a polyglot CI/CD pipeline handling Node.js, Java, and Rust services in parallel, GitOps-driven deployments via ArgoCD, and environment-aware security scanning that keeps developers fast without sacrificing rigour on the way to production.
Scope
This covers the full platform stack: infrastructure, containers, CI/CD, GitOps, and security — not just one layer.
Problem#
Most infrastructure tutorials stop at getting something running. Production platforms have harder constraints: multiple environments that can't interfere with each other, build pipelines that need to stay fast as the service count grows, and security controls that don't slow down every commit.
The challenge here was designing a system that held together across all of these dimensions at once — not just in one isolated area.
Solution#
I structured the build into six progressive phases:
- OIDC authentication — GitHub Actions authenticates to AWS via OpenID Connect. No long-lived access keys, no rotation burden. Credentials expire in one hour.
- Terraform environment isolation — Dev, staging, and production each have completely separate remote state (S3 + DynamoDB locking). Destroying dev cannot touch production.
- EKS with ECR — A Terraform-provisioned EKS cluster per environment, with ECR repositories for each service, image lifecycle policies, and IRSA for pod-level IAM.
- Advanced Kubernetes — HPA, Pod Disruption Budgets, Network Policies, RBAC, and StatefulSets. Built with Helm charts that carry production-safe defaults.
- Polyglot CI/CD — Matrix builds run Node.js, Java, and Rust services in parallel. Each language gets its own caching strategy (npm, Maven, Cargo) and optimised Dockerfile.
- Environment-aware security scanning — Fast scans on feature branches, comprehensive SAST and SCA on staging, full container and IaC scanning with manual approval gates on production.
Architecture#
The architecture runs three fully isolated environments — each with its own VPC, EKS cluster, and Terraform state. GitOps via ArgoCD drives deployments: automated to dev, one approval for staging, two approvals and a manual gate for production.
The EKS cluster provisioning is covered in more depth in a companion project:
Kubernetes Workload Platform on AWS EKS
Provisioned a production-grade EKS cluster on AWS with Terraform, deployed containerised workloads using Helm, and automated the full delivery pipeline with Jenkins.
Tech Stack#
- AWS EKS
- Terraform
- GitHub Actions
- ArgoCD
- Helm
- Docker
- ECR
- Prometheus
- Grafana
- OIDC
strategy:matrix: service: - name: node-api cache: npm build: npm ci && npm run build - name: java-service cache: maven build: mvn clean package -DskipTests - name: rust-processor cache: cargo build: cargo build --release # All three run concurrently.# Total build time: ~4 min (not 9 min sequential).The full design and trade-off analysis for this delivery system is documented in the case study:
Designing a secure internal delivery platform on AWS and Kubernetes
A deep technical breakdown of how infrastructure baselines, GitOps delivery, and observability defaults came together as a reusable internal platform.
Key Features#
- GitHub OIDC → AWS: no stored access keys, temporary credentials only.
- Complete Terraform state isolation per environment with S3 + DynamoDB.
- EKS cluster autoscaling, IRSA for pod IAM, ECR with lifecycle policies.
- Helm charts with HPA, PDB, Network Policies, and zero-downtime rolling updates.
- Parallel matrix builds for Node.js, Java, and Rust with language-specific caching.
- Tiered security scanning: fast on dev, comprehensive on staging, full suite on production.
- ArgoCD GitOps with automated dev sync and manual approval gates for production.
- Prometheus + Grafana observability baked into the platform defaults.
Media#
Results#
- Build times reduced from ~9 minutes (sequential) to ~4 minutes (parallel matrix builds).
- Zero long-lived AWS credentials — full OIDC adoption across all environments.
- Production deployments require 2 approvals and pass a full security suite before shipping.
- Terraform destroy of dev cannot affect staging or production state.
- Platform provides a consistent baseline any new service can land on from day one.
One concrete operational outcome from tightening the EKS delivery configuration:
Tightening EKS ingress health checks to make rollouts boring again
Reduced deployment friction by aligning ALB health checks, readiness behavior, and ingress expectations so rollout failures became faster to diagnose and less disruptive.
What this demonstrates
End-to-end platform engineering thinking: security, delivery, infrastructure, and operations handled as one coherent system rather than separate concerns bolted together.
Lessons Learned#
The biggest lesson was that platform work is primarily a coordination problem. The technology choices (EKS, ArgoCD, Terraform) are well understood. The harder part is designing the system so that environment isolation, security controls, and developer experience reinforce each other rather than pulling in different directions.
Building the tiered security scanning was a good example of this. Full scanning on every commit sounds rigorous, but it slows developers down and trains them to ignore CI. Environment-aware scanning — fast on dev, comprehensive on production — achieves better security outcomes by not making developers work around the system.
For deeper context on the Kubernetes delivery patterns used here, this post breaks down the internals:
Kubernetes Internals Notes: API Server, RBAC, Scheduling, and Controllers
A practical, student-friendly guide to the Kubernetes request flow, authentication vs authorization, controllers, scheduler behavior, rolling updates, and workload resilience.